数据结构 链表与跳跃表
编写测试环境
编写好测试工具和环境,下面就直接使用这些工具方法了
public class Test {
public static void main(String[] args) {
Node list = generateList(10, 99);
Node copy = copyList(list);
printList(list);
printList(copy);
}
/**
* 生成随机链表
*/
public static Node generateList(int len, int max) {
Node head = new Node(Integer.MIN_VALUE);
Node flag = head;
for (int i = 0; i < len; i++) {
flag.next = new Node((int) (Math.random() * max));
flag = flag.next;
}
return head.next;
}
/**
* 复制链表
*/
public static Node copyList(Node node) {
Node head = new Node(Integer.MIN_VALUE);
Node flag = head;
while (node != null) {
flag.next = new Node(node.value);
flag = flag.next;
node = node.next;
}
return head.next;
}
/**
* 打印链表
*/
public static void printList(Node node) {
while (node != null) {
System.out.print(node.value + " ");
node = node.next;
}
System.out.println();
}
/**
* 链表节点
*/
static class Node {
public Node next;
public int value;
public Node(int value) {
this.value = value;
}
}
}
反转单向和双向链表
题目:分别实现反转单向链表和反转双向链表的函数 要求:如果链表长度为 N,时间复杂度要求为 ,额外空间复杂度要求为
1、反转单向链表:
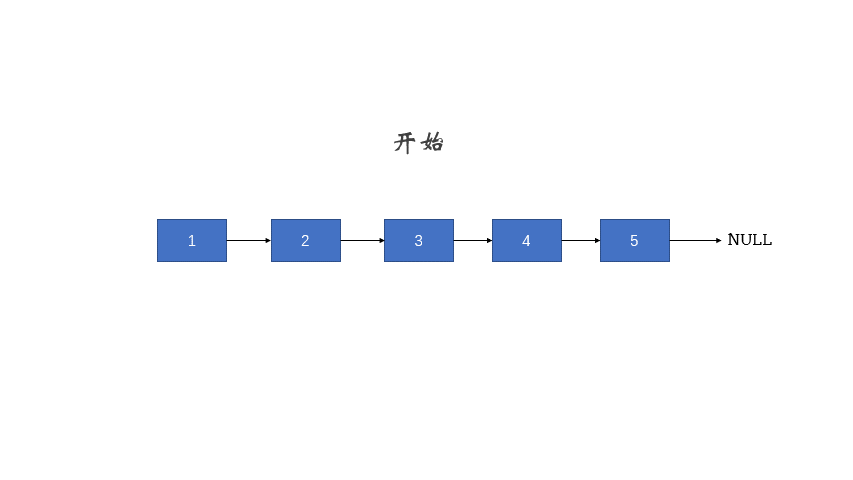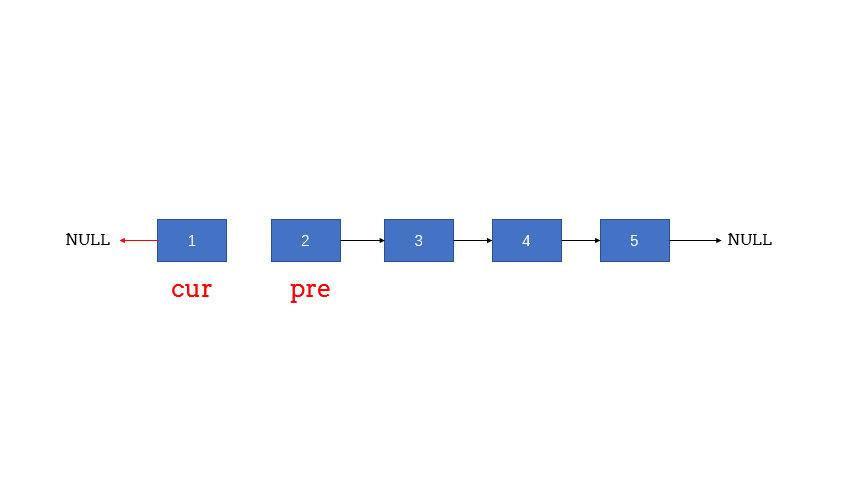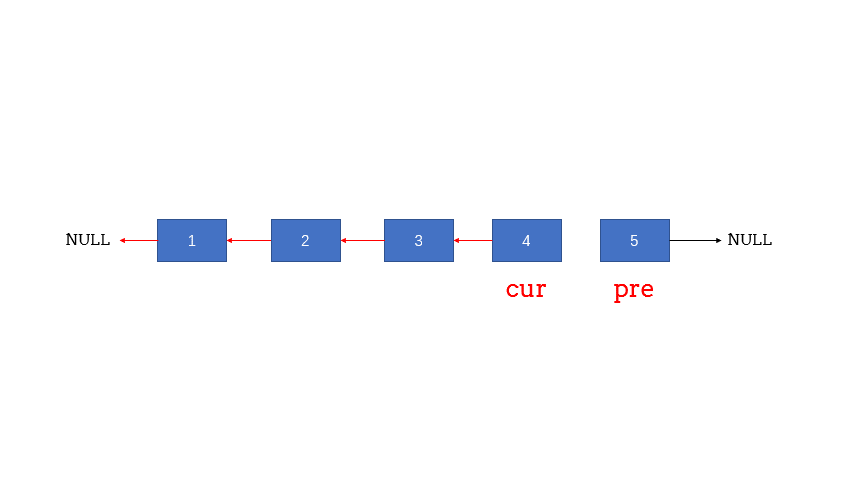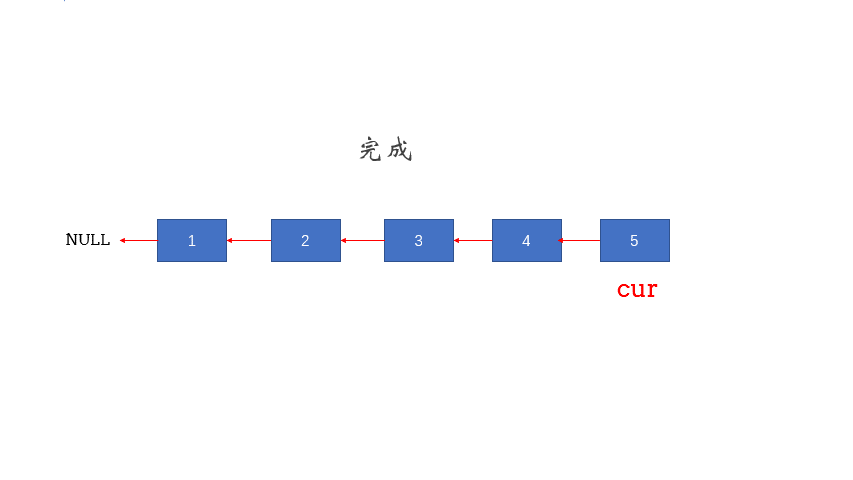
/**
* 反转单向链表,得用三指针法
*/
public static Node reversal(Node head) {
if (head == null || head.next == null) return head;
Node cur = null; // 前
Node pre = head; // 后
while (pre != null) {
Node temp = pre.next;
pre.next = cur;
cur = pre;
pre = temp;
}
return cur;
}
打印的结果:
反转前:34 76 13 33 10 77 77 94 98 12
反转后:12 98 94 77 77 10 33 13 76 34
2、反转双向链表
/**
* 反转双向链表
*/
public class Test2 {
public static class DoubleNode {
public int value;
public DoubleNode next;
public DoubleNode last;
public DoubleNode(int data){
this.value=data;
}
}
public static DoubleNode reverseList(DoubleNode head){
DoubleNode pre = null;
DoubleNode next = null;
while(head != null){
next = head.next;
head.next = pre;
head.last = next;
pre = head;
head = next;
}
return pre;
}
}
判断是否为回文结构
题目:给定一个单链表的头节点 head,请判断该链表是否为回文结构。 例子:1-2-1,返回 true;1-2-2-1,返回 true;15-6-15,返回 true;1-2-3,返回 false
如果链表长度为 N,时间复杂度达到 ,额外空间复杂度达到
方法一:使用栈的方式: 因为栈可以让链表变成逆序,而回文结构逆序等于正序
1 2 3 3 2 1
入栈后出栈
1 2 3 3 2 1
这种方式明显空间复杂度无法达到
方法二:使用快慢指针 快指针走两步,慢指针走一步,这样快指针走到终点,慢指针就走了一半
注意:实际 codeing 时需要考虑链表的奇偶
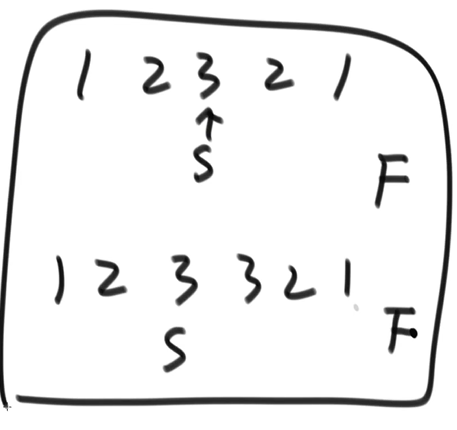
/**
* 回文串
*/
public static boolean isPalindrome(Node head) {
if (head == null) return false;
Node fast = head;
Node slow = head;
while (fast != null) {
fast = fast.next != null ? fast.next.next : null;
slow = slow.next != null ? slow.next : slow;
}
// 这时 slow 已经到了中点的位置; 反转后半部分的链表
Node cur = null;
Node pre = slow;
// reverse 逆序后半部分
while (pre != null) {
Node temp = pre.next;
pre.next = cur;
cur = pre;
pre = temp;
}
// 这时 cur 就是逆序的,这样就可以直接比较了
while(cur != null) {
if (cur.value != head.value) {
return false;
}
head = head.next;
cur = cur.next;
}
return true;
}
单链表划分
将单向链表按某值划分成左边小、中间相等、右边大的形式
[题目] 给定一个单链表的头节点 head,节点的值类型是整型,再给定一个整数 pivot。实现一个调整链表的函数,将链表调整为左部分都是值小于 pivot 的节点,中间部分都是值等于 pivot 的节点,右部分都是值大于 pivot 的节点。
[进阶] 在实现原问题功能的基础上增加如下的要求:
- 调整后所有小于 pivot 的节点之间的相对顺序和调整前一样
- 调整后所有等于 pivot 的节点之间的相对顺序和调整前一样
- 调整后所有大于 pivot 的节点之间的相对顺序和调整前一样
- 时间复杂度请达到 ,额外空间复杂度请达到 。
这题原理就是分别使用三个链表,最后拼接在一起
public static Node listPartition(Node head, int pivot) {
Node sH = null; // small head
Node sT = null; // small tail
Node eH = null; // equal head
Node eT = null; // equal tail
Node mH = null; // big head
Node mT = null; // big tail
Node next = null; // save next node
// every node distracted
while (head != null) {
next = head.next;
head.next = null;
if (head.value < pivot) {
// 第一次执行时进行初始化
if (sH == null) {
sH = head;
sT = head;
} else {
sT.next = head;
sT = head;
}
} else if (head.value == pivot) {
// 第一次执行时进行初始化
if (eH == null) {
eH = head;
eT = head;
} else {
eT.next = head;
eT = head;
}
} else {
// 第一次执行时进行初始化
if (mH == null) {
mH = head;
mT = head;
} else {
mT.next = head;
mT = head;
}
}
head = next;
}
// small and equal reconnect
if (sT != null) { // 如果存在小于区域
sT.next = eH;
eT = eT == null ? sT : eT; // 下一步,谁去连大于区域的头,谁就变成 eT
}
// 上面的 if,不管跑了没都是使用 eT 进行连接
if (eT != null) {
eT.next = mH;
}
return sH != null ? sH : (eH != null ? eH : mH);
}
复制含有随机指针节点的链表
[题目] 一种特殊的单链表节点类描述如下:
class Node {
int value;
Node next;
Node rand;
Node(int val) {
value = val;
}
}
rand 指针是单链表节点结构中新增的指针,rand 可能指向链表中的任意一个节点,也可能指向 null。给定一个由 Node 节点类型组成的无环单链表的头节点 head,请实现一个函数完成这个链表的复制,并返回复制的新链表的头节点。
【要求】时间复杂度 ,额外空间复杂度
方法一(不考虑空间复杂度,可以直接使用 HashMap):
public static Node copyListWithRand(Node head) {
HashMap<Node, Node> map = new HashMap<>();
Node cur = head;
while (cur != null) {
map.put(cur, new Node(cur.value));
cur = cur.next;
}
cur = head;
while (cur != null) {
map.get(cur).next = map.get(cur.next);
map.get(cur).rand = map.get(cur.rand);
cur = cur.next;
}
return map.get(head);
}
方法二,直接克隆(参考 左神的视频 1:55:00)
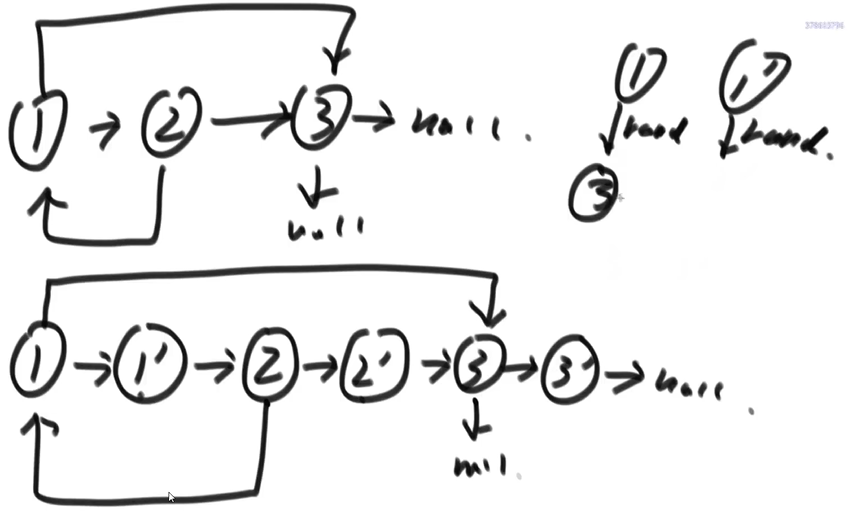
直接在被克隆的节点下一个位置创建一个克隆节点,然后再遍历一遍,让克隆节点指向下一个就行了
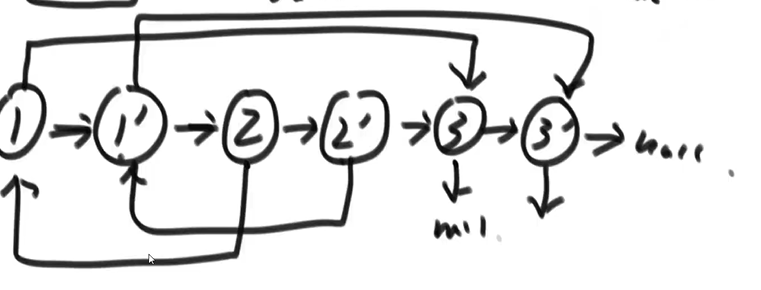
public static Node copyListWithRand2(Node head) {
if (head == null) {
return null;
}
Node cur = head;
Node next = null;
// copy node and link to every node
// 1 -> 2
// 1 -> 1' -> 2
while (cur != null) {
next = cur.next;
cur.next = new Node(cur.value);
cur.next.next = next;
// 指向 next
cur = next;
}
cur = head;
Node curCopy = null;
// set copy node rand
// 1 -> 1' -> 2 -> 2'
while (cur != null) {
next = cur.next.next; // 2
curCopy = cur.next; // 2'
curCopy.rand = cur.rand != null ? cur.rand.next : null; // 复制 rand 指向
cur = next;
}
Node res = head.next;
cur = head;
// split
// 1 -> 1' -> 2 -> 2'
while (cur != null) {
next = cur.next.next; // 2
curCopy = cur.next; // 2'
cur.next = next; // 1 -> 2 -> 2'
curCopy.next = next != null ? next.next : null; // 1' -> 2'
cur = next;
}
return res;
}
链表中倒数第k个节点(中等)
题目描述: 输入一个链表,输出该链表中倒数第k个结点。 如果该链表长度小于k,请返回空。
示例1
{1,2,3,4,5},1
返回值
{5}
暴力解法
import java.util.*;
/*
* public class ListNode {
* int val;
* ListNode next = null;
* public ListNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pHead ListNode类
* @param k int整型
* @return ListNode类
*/
public ListNode FindKthToTail (ListNode pHead, int k) {
if(pHead == null || k < 1) return null;
ArrayList<ListNode> array = new ArrayList<>();
while(pHead != null) {
array.add(pHead);
pHead = pHead.next;
}
if(array.size() < k) return null;
return array.get(array.size() - k);
}
}
快慢指针
解题思路:快慢指针,先让一个指针指向头节点,先走 K 步,如果为空就返回空,反之,就再让一个指针从头节点出发,快慢指针一起走,直到快指针为空,输出慢指针
即:倒数的 + 顺数的长度等于链表总长度,所以当 fast 指针为 null 时,剩下的慢指针所在的地方就是目标了
如下图所示

public ListNode FindKthToTail (ListNode pHead, int k) {
// write code here
if(pHead == null) return pHead;
ListNode fast = pHead;
int i = 0;
while(i < k){
if(fast == null) return fast;
fast = fast.next;
i++;
}
ListNode slow = pHead;
while(fast != null){
slow = slow.next;
fast = fast.next;
}
return slow;
}
如何判断存在循环链表?
给定一个链表,判断链表中是否有环。
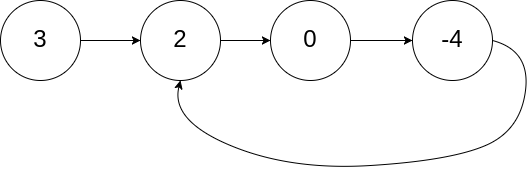
/**
* 判断数组是否是环
*/
private static boolean isCircularList(ListNode head) {
if (head == null || head.next == null) return false;
// 快慢指针,快指针一次移动两位,慢指针一次移动一位
ListNode fast = head;
ListNode slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (fast == slow) return true;
}
return false;
}
找到循环链表的入口位置
参考 左神的视频 0:11:00 流程,还是像上面那样快慢指针,关键是相遇后:快指针回到开头,慢指针位置不变,然后快慢指针同时移动(快慢指针都是每次移动一位),当它们再次相遇时,它们所在位置就是循环链表的入口位置,这个记住就好了,证明过程不去了
public static Node isCircularList(Node head) {
if (head == null) {
return null;
}
Node fast = head;
Node slow = head;
// 先让快慢指针相遇
do {
if (fast == null || fast.next == null) return null;
fast = fast.next.next;
slow = slow.next;
} while (fast != slow);
// 然后让 fast 回到 head
fast = head;
while (fast != slow) {
fast = fast.next;
slow = slow.next;
}
return slow;
}
链表的查找优化(跳跃表)
数组是如何优化查找的?都知道是二分查找,那链表能二分查找吗?也可以,就是使用跳跃表
跳表的查找、插入、删除的时间复杂度都是 O(logn)
跳跃表(skiplist)是一种随机化的数据,跳跃表以有序的方式在层次化的链表中保存元素, 效率和平衡树媲美。查找、删除、添加等操作都可以在对数期望时间下完成, 并且比起平衡树来说, 跳跃表的实现要简单直观得多。
以下是个典型的跳跃表例子

它主要有以下概念
- 表头(head):负责维护跳跃表的节点指针。
- 跳跃表节点:保存着元素值,以及多个层。
- 层:保存着指向其他元素的指针。高层的指针越过的元素数量大于等于低层的指针,为了提高查找的效率,程序总是从高层先开始访问,然后随着元素值范围的缩小,慢慢降低层次。
- 表尾:全部由 NULL 组成,表示跳跃表的末尾。
如何确定插入数据的层级
在确定要插入数据的层级时,跳表使用了一种随机化的策略,称为抛硬币(coin flipping)方法。当要插入一个新的节点时,从底层开始,向上层逐层决定是否将该节点添加到当前层级。每一次决策都通过抛硬币来确定是否应该在当前层级上添加节点。
在 Redis 中,跳表的层级分布是通过概率来确定的,而这个概率是固定的,无法直接调节。默认情况下,Redis 使用 1/4 的概率来确定一个节点在上一层级是否出现。这意味着每个节点在上一层级出现的概率为 25%。
具体来说,对于一个新的节点,从底层开始,每一层级都有一定的概率来决定是否将该节点添加到当前层级。通常情况下,每一层级添加节点的概率是 50%。如果抛硬币结果是正面,那么节点将被添加到当前层级;如果抛硬币结果是反面,那么节点不会被添加到当前层级,插入操作结束。
通过使用随机化的抛硬币方法,跳表可以在保持较好平衡性的同时,有效地加速搜索操作的效率。节点的层级分布也会影响跳表的高度,进而影响了跳表的性能。
需要注意的是,跳表的层级分布是基于概率的,并且插入数据的层级是随机确定的。因此,跳表的层级分布可能会因为数据的插入顺序和随机化算法的不同而有所差异。
跳表和红黑树的区别
跳表(Skip List)和红黑树(Red-Black Tree)都是常用的数据结构,用于实现有序的集合或映射。它们在某些方面有相似之处,但也有一些重要的区别。
以下是跳表和红黑树之间的几个区别:
结构复杂度:跳表是基于链表的结构,而红黑树是基于二叉搜索树的结构。跳表相对简单,不涉及平衡调整,只需保证每层链表有序即可。而红黑树需要维护平衡性,通过旋转和重新着色等操作来保持树的平衡。
插入和删除操作:跳表的插入和删除操作相对简单,只需修改相应的链表指针即可,时间复杂度为 O(log n)。而红黑树的插入和删除操作更复杂,需要进行平衡调整,时间复杂度也为 O(log n),但在实际操作中可能稍微慢一些。
内存占用:跳表相对于红黑树来说,可能占用更多的内存空间。跳表通过层级的方式提供快速查找,每个节点可能具有多个指针,因此在存储相同数量的元素时,跳表可能需要更多的内存。而红黑树是基于二叉搜索树的结构,每个节点只需要存储左右子节点的指针和一些额外的信息。
查询效率:在平均情况下,跳表和红黑树的查询效率都为 O(log n),但跳表通常在实际应用中能够取得更好的性能,尤其在并发环境下。这是因为跳表具有局部性原理,更容易利用缓存,而红黑树的节点访问相对更分散。
综上所述,跳表和红黑树在结构、操作复杂度、内存占用和查询效率等方面存在差异。选择使用哪种数据结构取决于具体的使用场景和需求。跳表适用于需要快速插入、删除和查询的情况,尤其在并发环境下具有优势。而红黑树适用于需要高效的有序集合或映射,并且能够提供更好的平衡性和稳定性。
MySQL 为啥不用跳表作为索引
MySQL并不使用跳表作为索引的主要原因是跳表在实践中并没有被广泛采用作为数据库索引结构,而B+树被普遍认为是更适合作为数据库索引的数据结构。下面是一些原因:
空间利用率:跳表相对于B+树来说,会占用更多的空间。跳表需要维护额外的指针结构,因此相同数据量的索引在跳表中占用的空间会更多,这可能导致磁盘空间的浪费。
插入和删除代价:跳表在插入和删除操作时,需要维护索引的层级结构,这可能导致更多的指针更新操作。而B+树的插入和删除操作相对更高效,因为它只需要进行局部的调整,不需要对整个索引结构进行重构。
缓存友好性:跳表的索引结构不连续,导致跳表的访问模式可能不够友好,容易造成缓存的失效。而B+树的索引结构是连续的,更适合利用磁盘块缓存和CPU缓存,提供更好的访问性能。
成熟度和广泛应用:B+树作为一种经典的索引结构,在数据库领域已经被广泛研究和使用。大量的数据库管理系统,包括MySQL,都使用B+树作为默认的索引结构,这意味着B+树经过了长时间的验证和优化,已经具备了良好的性能和稳定性。
虽然跳表在某些情况下可能具有一些优势,例如在某些特定的内存数据库或非关系型数据库中,但在关系型数据库管理系统(RDBMS)的背景下,B+树被普遍认为是更合适和可靠的索引结构,因此MySQL选择使用B+树作为索引的主要数据结构。